Installing and Configuring Cloudbase-Init on Windows for VCF Automation Guest Customization
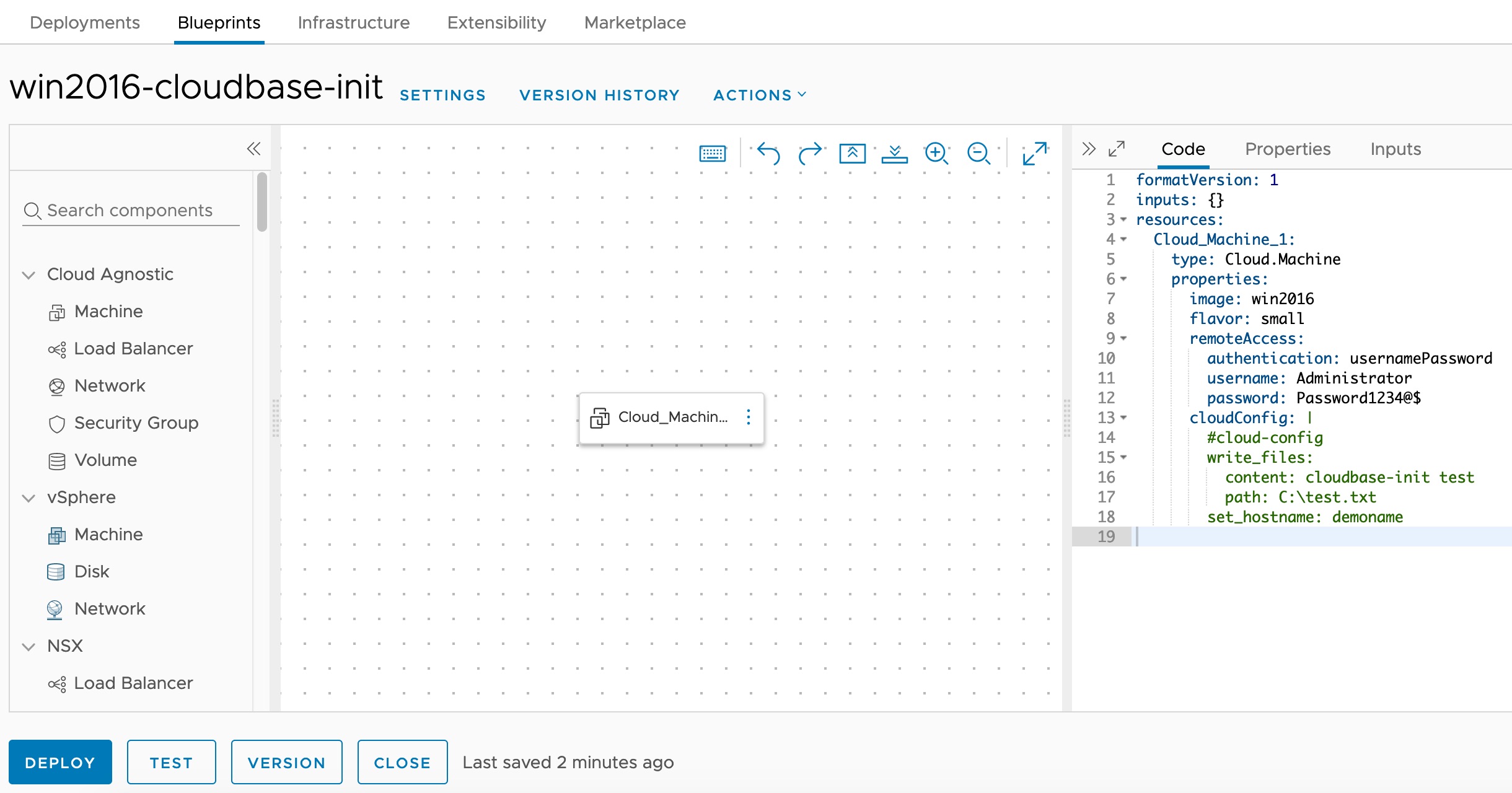
Customizing Windows guest instances in VMware environments has traditionally been handled by the VMware Guest Customization Specification (Sysprep-based). While this approach works, it has limitations — especially when you need cloud-agnostic blueprints that work across vCenter, Azure, AWS, and GCP cloud accounts. Enter Cloudbase-Init — the Windows equivalent of Cloud-Init. It provides powerful guest customization capabilities including user creation, password injection, hostname configuration, SSH public keys, and user-data script execution. This guide walks through the full process of installing and configuring Cloudbase-Init on a Windows Server template for use with VCF Automation (formerly VMware Aria Automation / vRealize Automation). ...